Ingeun Kim | ingeun92@naver.com | CURG
This article was originally written in Korean, and you can find it here !!
Deep learning has a major workflow of determining what kind of data has been input based on the learned features collected and trained. Utilizing this characteristic of deep learning, it has shown immense applicability in various fields such as image recognition, autonomous driving, and unmanned medical care. But are we sufficiently assured about the ever-advancing deep learning, or artificial intelligence in a broader sense?
This paper [1] focuses on the topic of “Uncertainty.” To understand this better, let’s first define what uncertainty means. Uncertainty refers to a state where the future cannot be predicted due to ambiguity or extreme fluctuations, according to the dictionary definition. From the perspective of artificial intelligence, uncertainty can be considered as a “lack of appropriate information needed for judgment or decision-making,” which may lead to incorrect judgments.
Although uncertainty has not received much attention in the deep learning field so far, it is an extremely important topic. For example, if deep learning is applied to autonomous driving or unmanned medical care and uncertainty is not properly addressed, serious accidents could occur. In fact, there was an incident where Google Photos failed to account for uncertainty and mistakenly recognized a black person as a gorilla, leading to an apology from Google [2]. Typically, deep learning models cannot say “I don’t know” when their results are incorrect.
The softmax algorithm, commonly used as the final activation function in deep learning models for multi-class classification problems, calculates the probability of each class. Although the softmax algorithm expresses the results of deep learning as probabilities, appearing to account for uncertainty, these probabilities do not reflect the uncertainty of the results. This is because when input data with a different distribution from the training data is fed into the model, it can produce completely incorrect results while the deep learning model presents them as if they were accurately predicted, which is problematic.
To address this uncertainty within deep learning, Bayesian neural networks have previously tackled the issue of uncertainty. However, applying Bayesian neural networks to deep learning is impractical due to their heavy computational requirements and resource-intensive nature. Therefore, this research proposes a method to apply uncertainty resolution to existing deep learning models with minimal resources.
The approach proposed in this paper is to equate Gaussian neural networks with Bayesian neural networks that can reflect uncertainty using dropout.
(This equivalence is derived mathematically through formulas, but to avoid making the content too dense and technical, the formulas have been omitted as much as possible.)
Bayesian Neural Networks
Essentially, in Bayesian neural networks [3], instead of fixing the weights during training, the probability distribution of the weights is determined. In other words, the weights are written on a die, and each time the die is rolled, a neural network with different weights emerges, effectively performing multiple neural networks.

Neural Networks with Dropout
Neural networks with dropout [4] share many similarities with Bayesian neural networks. First, instead of training on all neurons in the input layer or hidden layers, dropout-applied neural networks skip some neurons and train on the reduced network. As a result, different combinations of selected neurons lead to neural networks with different weights, effectively performing multiple neural networks, just like Bayesian neural networks.
Neural Networks with Dropout = Bayesian Neural Networks
As mentioned earlier, both NN-Dropout and BNN have the common characteristic of generating neural networks with different weights for each run, effectively performing multiple neural networks.
The formula below illustrates the similarity between NN-Dropout and BNN. By adjusting the formula to minimize the differences based on the objective similarity, the result of the NN-Dropout formula can become almost identical to the result of the BNN formula.

Sum Up
So, how did Bayesian neural networks calculate uncertainty? Applying this approach directly to NN-Dropout would achieve the goal of this paper.
The method for calculating uncertainty is as follows. Both NN-Dropout and BNN generate multiple models for each run. By feeding the same input into these generated models, multiple results are obtained. These results are then collected, and the mean and variance of the collected results are calculated. The calculated variance can be used as a measure of uncertainty.
Regression
The experimental results using NN-Dropout are shown in the following graph. The graph illustrates the uncertainty that arises when dropout is applied to various regression algorithms. The process up to the blue dotted line represents training on the training data, while the process after the blue dotted line represents feeding new test data unseen during training as input.
In the graph, (b), (c), and (d) show uncertainty as a dark blue shaded area. In (d), a very faint uncertainty can be observed because models using TanH tend to compress the output values more compared to ReLU, resulting in compressed uncertainty.
Note that MC Dropout in (c) and (d) stands for Monte Carlo Dropout, where the model uses dropout during both the training and testing processes.

Classification
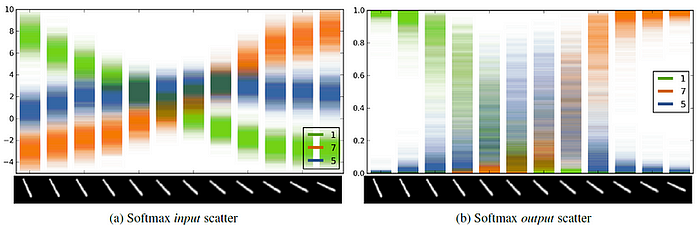
Let’s examine the uncertainty results for digit image recognition. The horizontal axis of the left and right graphs represents rotated images of the digit 1. The vertical axis of the left graph represents the scores for the output class from the softmax input, while the vertical axis of the right graph shows the probability values from the softmax output.
Here, the output exhibits greater uncertainty compared to the input, which is a result of reflecting uncertainty through dropout. Particularly, when the rotation of the digit 1 is around the middle, the left graph shows the highest score for classifying it as the digit 5. After passing through the softmax, the right graph displays a diffused and blurred shape, indicating high uncertainty.
This suggests that classifying the moderately rotated image of the digit 1 as the digit 5 has high uncertainty, and it would be advisable not to rely solely on the deep learning result in this case but to consider external opinions. This approach can help prevent accepting incorrect decisions made by deep learning models.
We have explored NN-Dropout, which inherits the characteristics of BNN while utilizing existing model structures and requiring fewer resources. While the proposed model in this paper is interesting, the author believes that the paper is valuable for highlighting the necessity of uncertainty research and offering a fresh interpretation of dropout. In addition to reading the paper itself, the author recommends watching a YouTube video that explains this paper [5].
References
[1] Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning | Yarin Gal, Zoubin Ghahramani
[2] Google, which recognized black people as gorillas… What has changed after 3 years? | Interviewz | https://m.blog.naver.com/businessinsight/221223724765
[3] Bayesian Deep Learning: Introduction | Taeoh Kim | https://taeoh-kim.github.io/blog/bayesian1/
[4] [Part 3. Neural Networks Optimization] 4. Dropout | Laon People Machine Learning Academy | https://m.blog.naver.com/PostView.nhn?blogId=laonple&logNo=220542170499&proxyReferer=https:%2F%2Fwww.google.com%2F
[5] PR-039: Dropout as a Bayesian approximation | Joonbum Cha | PR12 Deep Learning Paper Reading Group | https://www.youtube.com/watch?v=aU91bDGmy7I&list=PLlMkM4tgfjnJhhd4wn5aj8fVTYJwIpWkS&index=39
